では、インストールしたVirtuosoにRDF形式のデータをロードしてSPARQLをかけてみましょう。
今回はSPARQL習得をちょっぴり意識して、W3CのSPARQL1.1の仕様書のデータ&クエリを使ってみます。
Virtuosoには色々なデータのロード方法が用意されていますが、今回は一番簡単なGUIでのロードを行います。数M程度の小さなファイルをちょっとロードしたい、という場合には便利です。
ロードデータの準備
まずはロードするRDFファイルを準備します。
有志の方が翻訳してくれた日本語版のSPARQL1.1仕様書がありますので、その中の一つを使用します。
たとえば2.2章の「複数マッチ」の記載部分(リンク)にあるデータをコピーして、テキストエディタに貼り付けてローカルに保存します。この時のファイル名は任意ですが、拡張子は「.ttl」にしてください。
w3c_sparql11_2_2.ttl
|
1 2 3 4 5 6 7 |
@prefix foaf: <http://xmlns.com/foaf/0.1/> . _:a foaf:name "Johnny Lee Outlaw" . _:a foaf:mbox <mailto:jlow@example.com> . _:b foaf:name "Peter Goodguy" . _:b foaf:mbox <mailto:peter@example.org> . _:c foaf:mbox <mailto:carol@example.org> . |
データのロード
ロードするファイルが準備できたら、Virtuosoを起動させた状態でブラウザを開いて以下のURLにアクセスします。
http://localhost:8890/
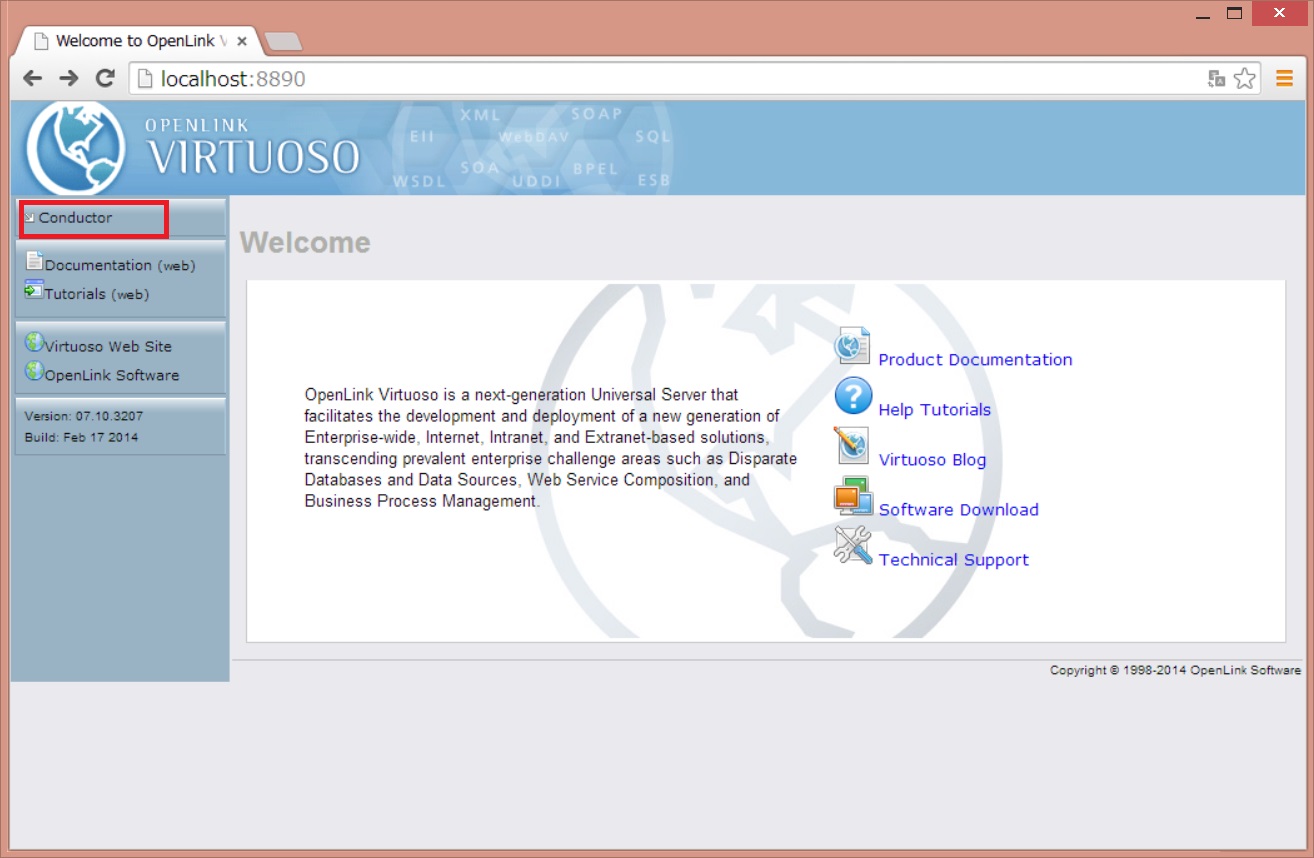
ログインのためのアカウントとパスワードを聞かれるので、初期値で両方とも[dba]と入力してログインしてください。
尚、dbaは管理者アカウントなので、セキュリティを気にする環境であれば、はじめにパスワードを変えておきましょう。パスワードはログイン後の画面の [System Admin] – [User Account] – [dba(Edit)]から変更できます。
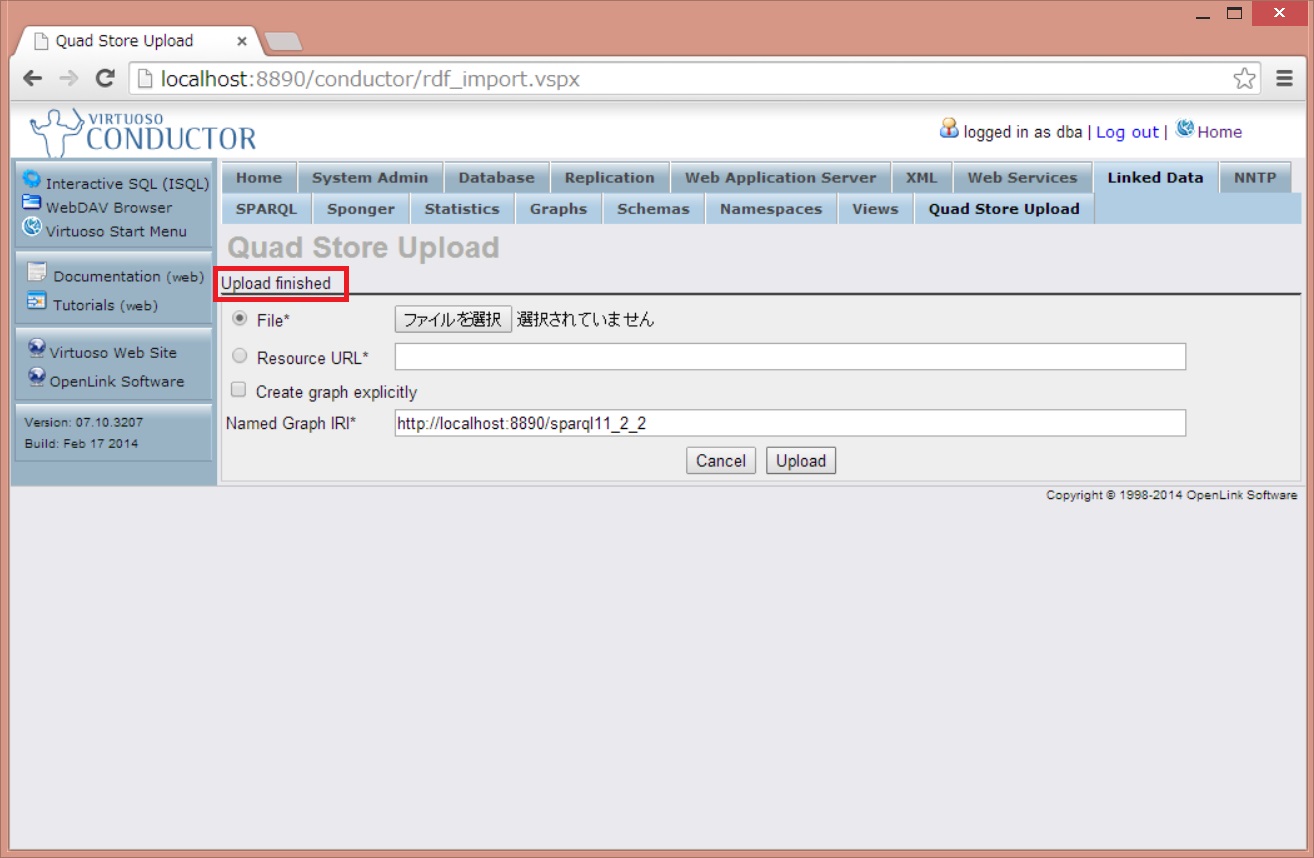
ログインができたら、[Linked Data] – [Quad Store Upload]からデータのアップロード画面を開きます。
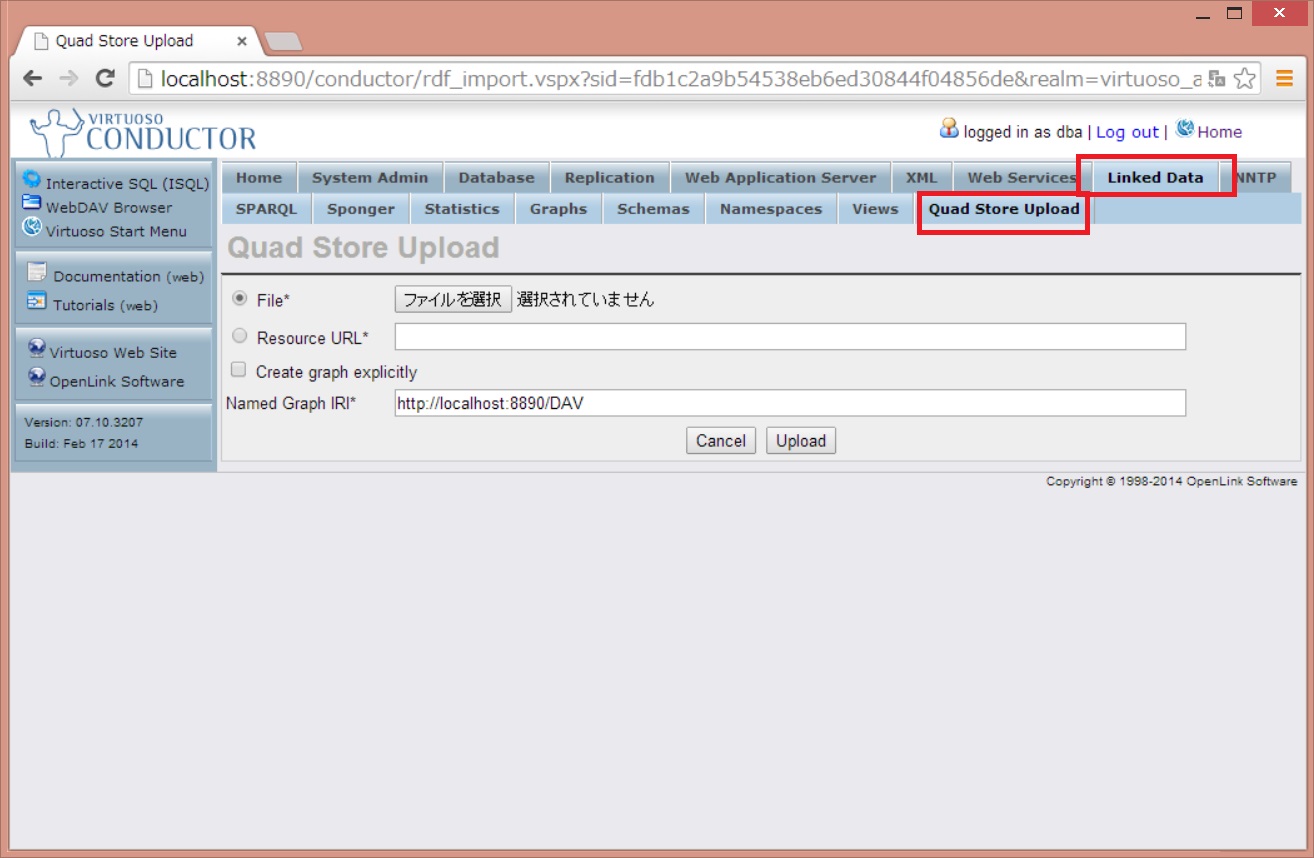
先ほど準備したロード用のファイルを選択し、アップロードするグラフ名を入力します。
グラフ名は任意の値で構いませんが、今回のファイルは「http://localhost:8890/sparql11_2_2」としてみます。
紛らわしくてよく間違えるのですが、左側は[Cancel]ボタンで右側が[Upload]ボタンになります。
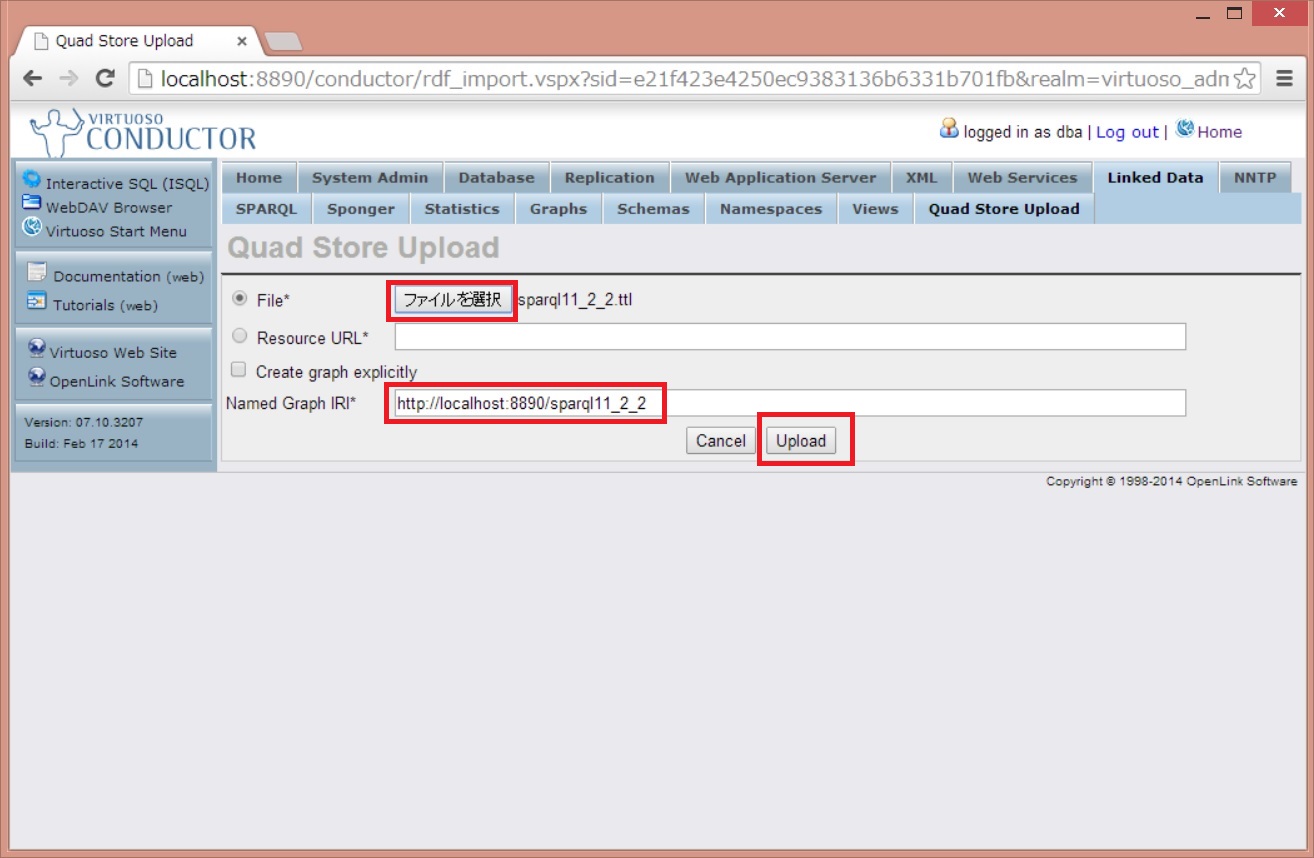
グラフ名をつけておくとロードするトリプルを一つのデータセットとして扱えます。最初のうちはRDBにおけるテーブルのような感覚でよいでしょう。
デフォルトのグラフ名のままでもロードはできますが、次々にファイルをロードした場合に同じグラフにデータが混ざってしまい、SPARQLを打った時に余計なデータまで返ってくることがあります。クエリの練習をしているうちは細かくグラフ名を指定して置いたほうがよいでしょう。
成功すると地味に「Upload finished」とメッセージが表示されます。
SPARQLを打ってみる
ロードしたデータに対してSPARQLを打ってみましょう。
先ほどSPARQL1.1仕様書のページから取得したデータに対するSPARQLを投げてみます。オリジナルクエリはこちら。
ここでSPARQLに一箇所だけ手を加えて、先ほどロード時に指定したグラフだけを検索対象にするようにします。具体的にはSELECTとWHEREの間にFROM句を追加してグラフを限定します。もしグラフ名を忘れた場合にはタブの[Graphs]から確認できます。
|
1 2 3 4 5 6 |
PREFIX foaf: <http://xmlns.com/foaf/0.1/> SELECT ?name ?mbox FROM <http://localhost:8890/sparql11_2_2> WHERE { ?x foaf:name ?name . ?x foaf:mbox ?mbox } |
タブで[SPARQL]を選択して、クエリを実行します。
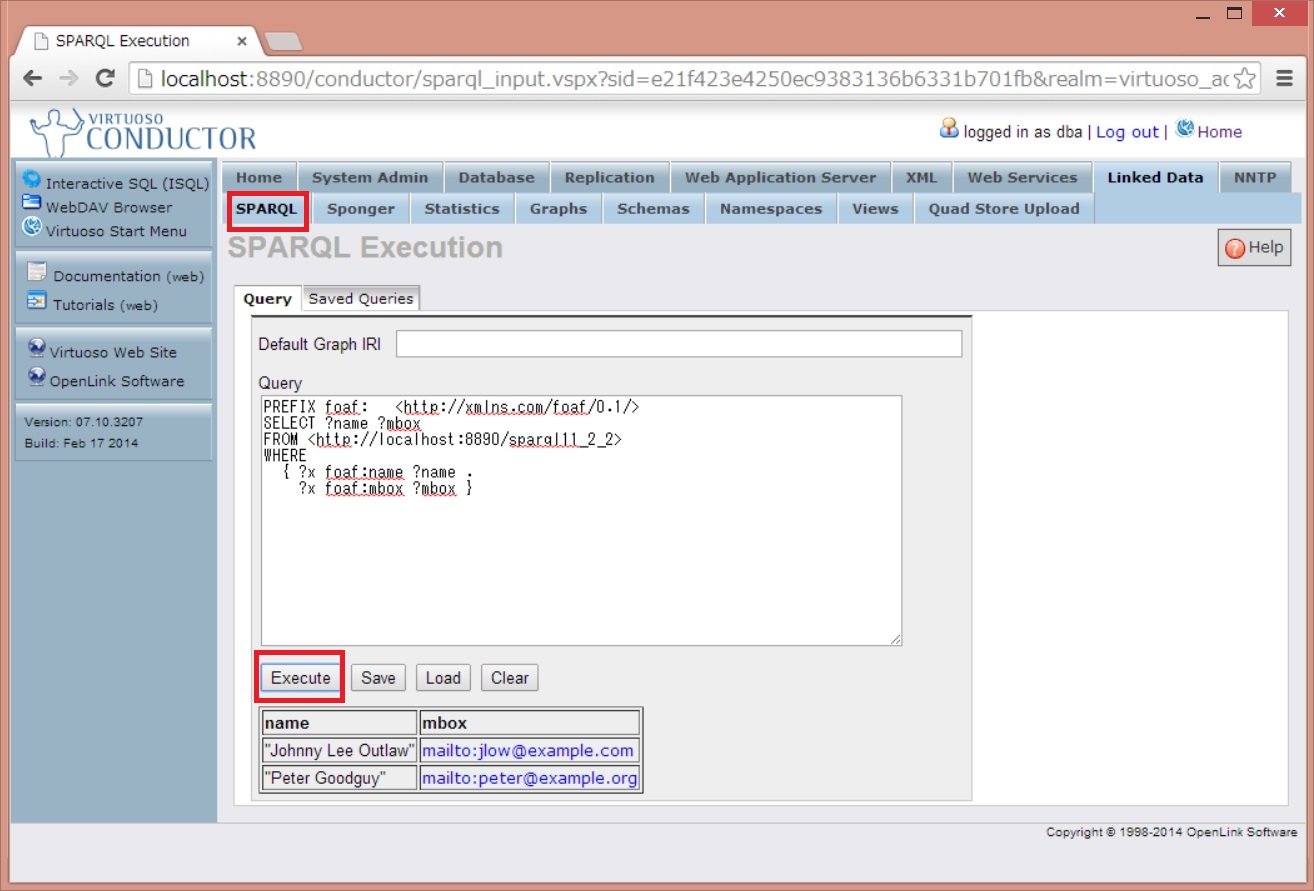
クエリ結果が SPARQL1.1仕様書に記載されているものと同じであることを確認してください。
仕様書を読んだだけでは分かりにくければ、こんな風に実際にSPARQLを試してみれば、理解を助けてくれるでしょう。
尚、ロードしたデータを削除したい場合には[Graphs] - [Graphs] で対象グラフの [delete]から消せます。